And that answer is good enough for most workloads. You should stop reading now.
_______________________
The complex answer is that there is some ability one CCD to pull cachelines from the other CCD. But I've never been able to find a solid answer for the limitations on this. I know it can pull a dirty cache line from the L1/L2 of another CCDs (this is the core-to-core latency test you often see in benchmarks, and there is an obvious cross-die latency hit).
But I'm not sure it can pull a clean cacheline from another CCD at all, or if those just get redirected to main memory (as the latency to main memory isn't that much higher than between CCDs). And even if it can pull a clean cacheline, I'm not sure it can pull them from another CCD's L3 (which is an eviction cache, so only holds clean cachelines).
The only way for a cacheline to get into a CCD's L3 is to be evicted from an L2 on that core, so if a dataset is active across both CCDs, it will end up duplicated across both L3s. Cachelines evicted from one L3 do NOT end up in another L3, so an idle CCD can't act as a pseudo L4.
I haven't seen anyone make a benchmark which would show the effect, if it exists.
I'm sure I've seen basic hill climbing (and other optimisation algorithms) described as AI, and then used evidence of AI solving real-world science/engineering problems.
Historically this was very much in the field of AI, which is such a massive field that saying something uses AI is about as useful as saying it uses mathematics. Since the term was first coined it's been constantly misused to refer to much more specific things.
From around when the term was first coined: "artificial intelligence research is concerned with constructing machines (usually programs for general-purpose computers) which exhibit behavior such that, if it were observed in human activity, we would deign to label the behavior 'intelligent.'" [1]
That definition moves the goalposts almost by definition, people only stopped thinking that chess demonstrated intelligence when computers started doing it.
The term artificial intelligence has always been just a buzzword designed to sell whatever it needed to. IMHO, it has no meaningful value outside of a good marketing term. John McCarthy is usually the person who is given credit for coming up with the name and he has admitted in interviews that it was just to get eyeballs for funding.
There are plenty of smart people in the "AI community" already who know it. Smugly commenting does not replace actual work. If you have real insight and can make something perform better, I guarantee you that many people will listen (I don't mean twitter influencers but the actual field). If you don't know any serious researcher in AI, I have my doubts that you have any insight to offer.
I'm really not sure if POWER1 and PowerPC 603 should be counted as OoO or not.
It's certainly not the same kind of OoO. They had register renaming¹, But only enough storage for a few renamed registers. And they didn't have any kind of scheduler.
The lack of a scheduler meant execution units still executed all instructions in program order. The only way you could get out-of-order execution is when instructions went down different pipelines. A floating point instruction could finish execution before a previous integer instruction even started, but you could never execute two floating point instructions Out-of-Order. Or two memory instructions, or two integer instructions.
While the Pentium Pro had a full scheduler. Any instruction within the 40 μop reorder buffer could theoretically execute in any order, depending on when their dependencies were available.
Even on the later PowerPCs (like the 604) that could reorder instructions within an execution unit, the scheduling was still very limited. There was only a two entry reservation station in front of each execution unit, and it would pick whichever one was ready (and oldest). One entry could hold a blocked instruction for quite a while many later instructions passed it through the second entry.
And this two-entry reservation station scheme didn't even seem to work. The laster PowerPC 750 (aka G3) and 7400 (aka G4) went back to singe entry reservation stations on every execution unit except for the load-store units (which stuck with two entries).
It's not until the PowerPC 970 (aka G5) that we see a PowerPC design with substantial reordering capabilities.
¹ well on the PowerPC 603, only the FPU had register naming, but the POWER1 and all later PowerPCs had integer register renaming
What I find interesting is that Intel engineers actually designed their own 64-bit extension, somewhere along the same lines as AMD64.
Intel's marketing department threw a fit, they didn't want the Pentium 4 competing with their flagship Itanium. Bob Colwell was directly ordered to remove the 64-bit functionality.
Which he kind of did, kind of didn't. The functionally was still there, but fused off when Netburst shipped.
If it wasn't for AMD beating them to market with AMD64, Intel would have probably eventually allowed their engineers to enable the 64-bit extension. And when it did come time to add AMD64 support to the Pentium 4 (later Prescott and Cedar Mill models) the existing 64-bit support probably made for a good starting point.
Around the time of K8 being released, I remember reading official intel roadmaps announced to normal people, and they essentially planned that for at least few more years if not more they will segment into increasingly consumer-only 32bit and IA-64 on the higher end
They were trying to compete with Sun and IBM in the server space (SPARC and Power) and thought that they needed a totally pro architecture (which Itanium was). The baggage of 32-bit x86 would have just slowed it all down. However having an x86-64 would have confused customers in the middle.
Think back then it was all about massive databases - that was where the big money was and x86 wasn't really setup for the top end load patterns of databases (or OLAP data lakes).
In the end, Intel did cannibalize themselves. It wasn’t too long after the Itanium launch that Intel was publicly presenting a roadmap that had Xeons as the appealing mass-market server product.
Yeah they actually survived quite well. Who knows how much they put into Itanium but in the end they did pull the plug and Xeons dominated the market for years.
They even had a chance with mobile chips using ATOM but ARM was too compelling and I think Apple was sick of the Intel dependency so when there was an opportunity in the mobile space to not be so deeply tied to Intel they took it.
I think the difference was that replacing Itaniums with Xeons on the roadmap didn't seriously hurt margins (probably helped!)
The problem with mobile was that it fundamentally required low-margin products, and Intel never (or way too late) realized that was a kind of business they should want to be in.
> and thought that they needed a totally pro architecture (which Itanium was).
Was it though ? They made a new CPU from scratch, promissing to replace Alpha, PA-RISC and MIPS, but the first release was a flop.
The only "win" of Itanium that I see, is that it eliminated some competitors in low and medium end server market: MIPS and PA-RISC, with SPARC being on life support.
The deep and close relationship of Compaq with Intel meant that it also killed off Alpha, which unlike MIPS and PA-RISC wasn't going out by itself (Itanium was explicitly to be PA-RISC replacement, in fact it started as one, while SGI had issues with MIPS. SPARC was reeling from the radioactive cache scandal at the time but wasn't in as bad condition as MIPS, AFAIK)
I never used them but my understanding is that the performance was solid - but in a market with incumbents you don't just need to be as good as them you need to be significantly better or significantly cheaper. My sense was that it met expectations but that it wasn't enough for people to switch over.
Merced (first generation Itanium) had hilariously bad performance, and its built in "x86 support" was even slower.
HP-designed later cores were much faster and omitted x86 hardware support replacing it with software emulation if needed, but ultimately IA-64 rarely ever ran with good performance as far as I know.
Pretty sure it was Itanium that finally turned "Sufficiently Smart Compiler" into curse phrase as it is understood today, and definitely popularized it.
> It’s as if they actually bought into the RISC FUD from the 1990’s that x86 was unscalable, exactly when it was taking its biggest leaps.
That's exactly what was happening.
Though it helps to realise that this argument was taking place inside Intel around 1997. The Pentium II is only just hitting the market, it wasn't exactly obvious that x86 was right in the middle making its biggest leaps.
RISC was absolutely dominating the server/workstation space, this was slightly before the rise of the cheap x86 server. Intel management was desperate to break into the server/workstation space, and they knew they needed a high end RISC cpu. It was kind of general knowledge in the computer space at the time that RISC was the future.
Exactly! But this was not just obvious in retrospect, it was what Intel was saying to the market (& OEMs) at the time!
The only way I can rationalize it is that Intel just "missed" that servers hooked up to networks running integer-heavy, branchy workloads were going to become a big deal. OK, few predicted the explosive growth of the WWW, but look around at the growth of workgroup computing in the early 1990's and this should have been obvious?
I'm not sure thats a fair description of server workloads. I'm also not sure it's fair to say Itanium was bad at integer-heavy, branchy workloads (at least not compared to Netburst)
The issue is more that server workloads are very memory bound, and it turns out the large OoO windows do an exceptional job of hiding memory latency. I'm sure the teams actually building OoO processors knew this, but maybe it wasn't obvious outside them.
Besides, Itanium was also designed to hide memory latency with its very flexible memory prefetch systems.
The main difference between the two approaches is static scheduling vs dynamic scheduling.
Itanium was the ultimate expression of the static scheduling approach. It required that mythical "smart enough compiler" to statically insert the correct prefetch instructions at the most optimal places. They had to strike a balance simultaneously wasting resources issuing unneeded prefetches and unable to issue enough prefetches because they were hidden behind branches.
While the OoO x86 cores had extra runtime scheduling overhead, but could dynamically issue the loads when they were needed. An OoO core can see branches behind multiple speculative branches (dozens of speculative branches on modern cores). And a lot of people miss the fact than an OoO core can actually take the branch miss-predict penalty (multiple times) that are blocked behind a slow memory instruction that's going all the way to main memory. Sometimes the branch mispredict cycles are entirely hidden.
In the 90s, static scheduling vs dynamic scheduling was very much an open question. It was not obvious just how much it would fall flat on its face (at least for high end CPUs).
Well, TBH it wasn't all FUD - hanging on to x86 eventually (much later) came back to bite them when x86 CPUs weren't competitive for tablets and smartphones, leading to Apple developing their own ARM-based RISC CPUs (which run circles around the previous x86 CPUs) and dumping Intel altogether.
It is interesting how so much of the speculation in those days was about how x86 was a dead end because it couldn’t scale up, but the real issue ended up being that it didn’t scale down.
Well, it turns out that it could scale up, it just needed more power than other architectures. As long as it was only servers and desktop PCs, you only noticed it in more elaborate cooling and maybe on your power bill, and even with laptops, x86 compatibility was more important than the higher power usage for a long time. It's just when high-performance CPUs started to be put in devices with really limited power budgets that x86 started looking really bad...
From a standards design perspective, there is nothing wrong with it. It's the same protocol running on two very different frequency bands. They co-exist and support each other.
They should share a specification (I know this is correctly called a 'standard') but the should have been a separate logo for each non-interoperable group of useful features (a different concept also often called a 'standard'); as USB has proved.
> The upshot is that the PIO can do multiple bit-shifts in a single clock cycle... it's likely there are clever optimizations in the design of the actual PIO that I did not implement
I was curious, so looked into this. From what I can tell, PIO can only actually do a maximum of two shifts per cycle. That's one IN, OUT, or SET instruction plus a side-set.
And the side-set doesn't actually require a full barrel shifter. It only ever needs to shift a maximum of 5 bits (to 32 positions), which is going to cut down its size. With careful design, you could probably get away with only a single 32-bit barrel shifter (plus the 5-bit side-set shifter).
Interestingly, Figure 48 in the RP2040 Datasheet suggests they actually use seperate input and output shifters (possibly because IN and OUT rotate in opposite directions?). It also shows the interface between the state machine input/output mapping, pointing out the two seperate output channels.
Barrel shifters are one of those things that end up a lot bigger in FPGAs than ASICs. Not really because a barrel shifter is harder, but because FPGAs optimise for most other common building blocks and barrel shifters are kind of left behind.
But even on the real RP2040, PIO is not small.
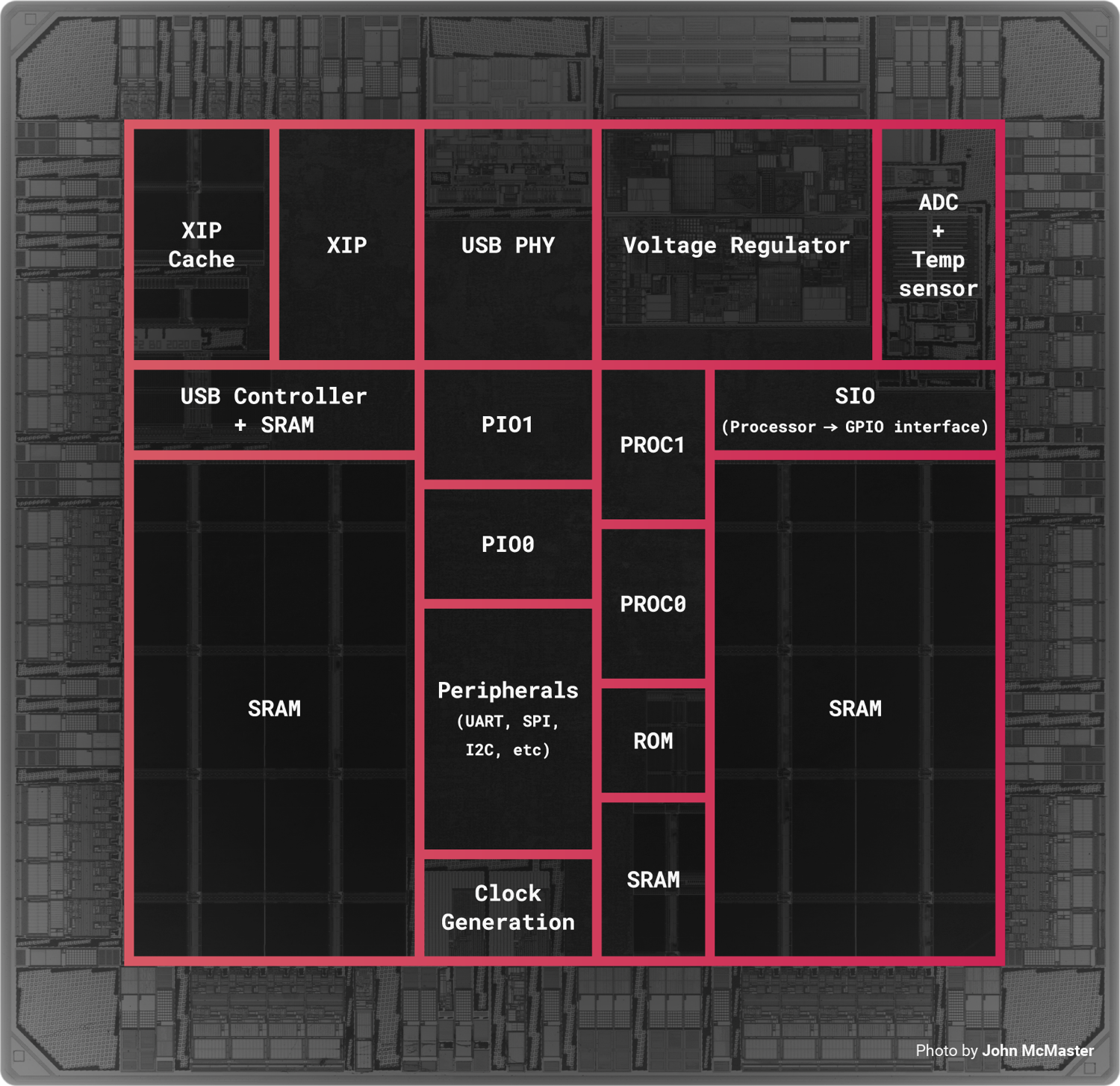
Take a look at the annotated die shot [0]. The PIO blocks are notably bigger than the PROC blocks.
It's hard to know for sure, because we don't have access to the PIO's implementation, but I suspect that the PIO is "not small".
That being said - size isn't everything. At these small geometries you have gates to burn, and having access to multiple shifts in a single cycle really do help in a range of serialization tasks.
It was apparently hidden in the lead-in area, but I can't find any information on how it was encoded. Some sources say "a hidden sector in the lead in" but that doesn't seem right, as there is nothing physically stopping a DVD burner with custom firmware from writing a hidden sector.
The disk key is small (40 bits) and I'm suspicious it's actually encoded as wobble frequency [0], like the PS1's copy protection scheme.
Because CD/DVD burners can't write wobble. Blank CDs/DVDs ship with a pre-made wobble in the pre-groove, which the burners use to determine the absolute position of the write laser.
But you couldn't rip the copy protection signal (not that you needed to, it was a fixed 4 letter string, "SCEA", "SCEI", or "SCEE" depending on region)
Nor could you burn it onto a CD-R. It was there to prevent people from burning copies of games, not to prevent you from ripping the disc.
Of course, it was stupidly easy to bypass with a mod chip. They literally just sit there injecting the copy protection signal into the cd rom electronics, tricking it into thinking every single disc was blessed by Sony, burned or not.
Not needed for emulation. I never owned a PSX so I used EPSXE and whatever I got for the N64 in early 2000s. I jumped from a GB/NES in late 90's to a PC. It was like crossing a wormhole to another dimension.
In this era, console designers were't concerned about emulators or ripping games. They were entirely focused on preventing game duplication (especially with CDs being so easy to copy) and unlicensed games. And the PS1's copy protection makes an ok effort at being a roadblock to running non-sony discs.
In fact, the question of emulators wouldn't have been on the Sony engineers minds at all.
Because in 1994 (when the ps1 launched) there were no viable console emulators.
There were a few early prototypes, but they didn't produce 'playable results'. The first viable emulator (for any console) was arguably NESticle, released in April 1997. Things then moved rapidly, we see the first viable 16bit emulators in 1998.
It's notable that the PS2 doesn't have any protection against ripping games either. The Sony engineers would have been aware of emulators by this point, but they might have assumed that emulation would be stuck in the 8/16bit era for the foreseeable future.
So it must have been a huge shock for the first viable 32bit era emulators to come out in 1999. Connectix Virtual Game station (Jan 1999), UltraHLE (Also Jan 1999) and Bleem! (March 1999)
Yes.. that's right. We went from the first viable NES emulator to viable PS1/N64 emulators in under 2 years.
I'm guessing the PS2 was a little too close to it's March 2000 release date at this point to slap on rip protection, but the Gamecube and Xbox were released 18 months later, and both had time to implement disc encryption schemes.
By 1994-1995 only the spoiled kids got the PS1. Again, I was 8-9 in that era. Most people resorted to a Chinese NES clone in tons of places. You talk about story, I talk about experience. By 1997-1998, yes, tons of people got it because it was a cheap CD player too, cheaper than a dedicated music set with speakers. But it wasn't odd to find some kid with parents working in an office or working as teachers, so they would have a PC and a CD burner (and elder brothers in college with computers too).
A few years later, months before the PS2/GC era, even at DC times (and good PC games) some PSX games were still emulated because they had tons of value, such as JRPGs. And, again, ripping PSX games to play them in emulators without risking to scratch the CD's was the same task as ripping them to play the games with a modchip.
Also, technologically JRPG's and survival horrors were
nothing against Unreal engine based games so they paled
against Deus Ex for instance, but man, Parasite Eve
and Resident Evil looked good with just a bilinear
filter and they ran in a potato.
On being a shock, not much, because somehow in my mind the PSX games were closer in architecture to a PC than a Game Boy ROM emulated on a PC, which looked like black magic, ignoring how the hell the nerd brainiacs dumped the cartridge content (I had no concept of EE burned ROM's in the day, or cartridge dumpers via the serial cable) to a PC. For the PSX, well, it was easier for obvious reasons, CD's were CD's, and again the 'look' of PC games and the PSX looked similar, so maybe they shared similar technologies on drawing/rendering.
Ditto with the N64, that was a bigger shock. How the hell did they dumped the content of the cartridge? Later I knew about Debian Woody, a bit of C, the concept of libraries (not just DLL's under Windows) and that the N64 and PC's with Linux with OpenGL shared some design and the rest was story. I learnt more about computers trying to write some emulator myself in Perl back in the day and with GNU/Linux than in any school...
Also I loved TV tuners for a similar reason. I could dump teletext, dump the EPG from cable TV's even with just plain TV tuners (the decoded signal went vanilla into the PCI bus, so NXTVEPG worked in the same exact way) and so on.
And yes, I pirated TV channels for some brief time until everyone shared media in either DivX CD's and P2P networks.
That's kind of my point... You are looking at it from the perspective of a western 90s kid who quickly adopted emulators (I am too). Of course it seems obvious to you that Sony should have encrypted the discs or something. Of course it seems obvious that emulation was inevitable.
But to understand Sony's development decisions, you really have to think in the mindset of an adult hardware engineer, in Japan, around 1992/1993.
And like I said, emulators did not exist. At all. The primary method of piracy was actually the game backup device [0]. We didn't really see them in the west, I'm not surprised you missed them, but they were rampant in Asia.
They were floppy drives that plugged into your carriage based console, SNES MegaDrive etc. They could dump any cartridge game to a floppy disk (or two in the case of the largest 2MB games). And then load the dump back into a pool of battery-backed RAM, which the console would see as a cartridge.
Owners of such devices could share the floppies, or copy the files off and share them across the internet.
These devices are why most cartridge game from the 8bit era, 16bit era and N64 (yes, there were N64 backup devices too) was already floating around the internet long before we had viable emulators.
And it's also what Sony Engineers would have been thinking about when they were designing their copy protection system. They didn't really see the need to prevent ripping (besides required cryptography hardware was expensive and actually considered to be controlled military technology, subject to strict export controls until 1996).
And Sony didn't see the need to prevent rips; All piracy devices at this point required the game to be played back on an actual offical console (ignoring Chinese NES clones), so all they needed to do was could close the circle by making the PS1 refuse to play any copied disc. No point ripping if they couldn't be played.
Of course, in retrospect this was a complete failure. Turns out mod chips for the PS1 were stupidly simple, cd burners rapidly dropped in price, and emulators quickly became viable.
The steaming services won't have lost any money on this.
It's the advertisers who paid for ads to get played to the bot accounts, and (depending on how the advertising deals were structured) other artists with legitimate listeners might have received smaller revenue cuts.
{kind=link}
And that answer is good enough for most workloads. You should stop reading now.
_______________________
The complex answer is that there is some ability one CCD to pull cachelines from the other CCD. But I've never been able to find a solid answer for the limitations on this. I know it can pull a dirty cache line from the L1/L2 of another CCDs (this is the core-to-core latency test you often see in benchmarks, and there is an obvious cross-die latency hit).
But I'm not sure it can pull a clean cacheline from another CCD at all, or if those just get redirected to main memory (as the latency to main memory isn't that much higher than between CCDs). And even if it can pull a clean cacheline, I'm not sure it can pull them from another CCD's L3 (which is an eviction cache, so only holds clean cachelines).
The only way for a cacheline to get into a CCD's L3 is to be evicted from an L2 on that core, so if a dataset is active across both CCDs, it will end up duplicated across both L3s. Cachelines evicted from one L3 do NOT end up in another L3, so an idle CCD can't act as a pseudo L4.
I haven't seen anyone make a benchmark which would show the effect, if it exists.
reply