I've been kicking around an idea like this for a while. The train of thought that brought me there was the recognition of a distinct memory hierarchy in today's common distributed applications that parallels the one in your computer.
So your computer has memory banks that (as a rough first approximation) each get ~10x bigger, but with ~10x greater latency. The neat part though is that global consistency for writes happens with L1 and L2 working together, so pretty damn high up in the hierarchy. In contrast distributed applications typically at best will have a write through cache where global consistency happens all the day down at the actual data store. Exploring the idea of distributed MOESI where one client, because they had the permissions to write something in the first place, can then be the owner for that database row as it's still being flushed out seems like a great basis for a distributed system that might not even need the dedicated datastore at all anymore, but a sea of clients participating in coherency and replication. Albeit this has oodles of consistency and availability problems that very well might kill the whole concept, like how MOESI would absolutely fall over when trying to hotplug CPUs at arbitrary times.
Maybe not directly related but this reminds of a paper[1] by Microsoft Research where they replicate state with DMA (Direct Memory Access) across the network and battery backups that have just enough power to flush memory to disk if the power goes out. you might find it interesting
> In contrast distributed applications typically at best will have a write through cache where global consistency happens all the day down at the actual data store. Exploring the idea of distributed MOESI where one client, because they had the permissions to write something in the first place, can then be the owner for that database row as it's still being flushed out seems like a great basis for a distributed system that might not even need the dedicated datastore at all anymore, but a sea of clients participating in coherency and replication.
Modern commercial distributed file systems do the type of caching you’re talking about. More generally, a Distributed Lock Manager [1] gets you halfway there. You’re right that a write-through cache is still necessary to achieve redundancy requirements, but especially in the context of file systems you can often coalesce local edits until the user explicitly issues stage equivalent of a flush operation, and only do the write-through then.
Love this. We’re building a similar architecture at Splitgraph [0] which we refer to as a “Data Delivery Network.” The basic idea is we implement a proxy that forwards queries to backend data (either live data sources via an FDW, or versioned snapshots via our Docker-inspired “layered querying”).
Soon anyone will be able to connect data sources by adding their read only credentials in the web (already possible via CLI but undocumented). The idea is to make exposing a database to the DDN as simple as exposing a website to a CDN.
We’ve designed all this to be multi-tenant and horizontally scalable, but we’re not actually running it on a distributed network yet. Personally, I’ve followed Fly for a long time and always loved the angle you’re taking. If any of you at Fly read this and want to potentially collaborate on a solution in this space, my email is in my profile.
I work at Socrata, and I've skimmed splitgraph and it looks pretty neat. How do you all deal with pushdowns or query rewriting in general when the target datasource doesn't implement the functionality your user writing real sql is trying to use? Does it explode or take forever, because it doesn't look like you're storing copies of everything in Real Postgres?
We expose a pretty limited subset of sql through our APIs, and an even more limited form to public APIs, so I'm interested in how you're doing things providing joins to your users. "It exists but is super slow" is a reasonable answer as well :)
Hey! Socrata is awesome :) The basic idea here is that you can write a Splitgraph plugin for any type of data source [0], so we like to use Socrata as a convenient example. Each plugin includes a Postgres Foreign Data Wrapper (FDW) to translate from SQL to whatever upstream query language (e.g. Socrata FDW [1]).
By default we don't copy any data into Splitgraph (although we do cache query results keyed by AST). When a query arrives, we parse it for any table identifiers, and "mount" a temporary foreign table for each, using the appropriate FDW. Foreign tables are mostly transparent to the Postgres query planner, so a JOIN will work (example [2]), and an FDW can even optionally implement aggregate pushdown. But yes, especially in the case of cross-dataset JOINS, there are some pathological cases. When your use case outgrows live querying (e.g. due to pathological JOIN queries), you can ingest any data source into a Splitgraph image, a versioned snapshot of data similar to a Docker image. [3]
Our focus right now is on the internal enterprise use case. We use the Socrata plugin as a demo, but our customers are more interested in plugins for data sources they use internally, e.g. Postgres, Snowflake, Google Search Console, CSV in S3, etc. We support all those too; you can mount them all locally, and you can also mount them on Splitgraph.com (or an internal deployment), but still thin docs / no web UI yet.
Hey Chatmasta, splitgraph is cool! Looking forward to use it for a project and meanwhile I've added it to my curated list of startup tools at StartupToolchain[1], I hope that's fine.
The way this is implemented, with the ability for an application server attached to a replica to say "error: this needs to perform a write - hey CDN, replay this request against the region with the database leader in it" is SO clever.
I think most database engineers who think about ACID/isolation levels/etc would look at this and go "uhm... jumps out a window" but for a subset of users I guess it kind of works?
I don't really see how a transaction that performs reads and writes can be replayed like this with any sort of guarantee about anything, though.
And there's no opportunity to build any sort of conflict resolution in there because the replay is automatic.
The replay is only automatic if you opt for the version where you catch write errors and turn them into replay requests.
My experience of building web apps, where most business logic runs within the scope of a single HTTP request, suggests that a quite impressive number of common cases could be served by the replay-request-against-the-leader pattern.
I mean: just to be clear: you can't write to a read replica. There's no way to introduce a conflict that way.
Also just for what it's worth: we agree with 'foobarbazetc. There's a section about that in the post. If you're saying there are important classes of applications this doesn't work well for, that's true.
Just to be clear, I'm not trying to say it's bad or whatever. It's super cool! I'm a big fan of fly.io.
I just don't see how something like this actually works in a way where you can reason about transaction ordering without global serialisation of requests against the writable database, which I presume isn't happening behind the scenes?
Basically, this would seem to work great if every request did INSERTs only and you based no logic to run INSERTs on anything you SELECT'ed from the read only replicas.
But you could have situations where, e.g., you DELETE or UPDATE something in a request to one region, and it goes to replay that against the writable region, and in "replay gap" another request modifies the same rows or objects, and based on various factors such as latency etc, a DELETE ... WHERE or UPDATE ... WHERE clause might no longer hold. Or you UPDATE the wrong objects, or DELETE the wrong data, etc.
I did read the post, but I guess I need to re-read it. I have written a globally distributed database before so I'm always intrigued by how these work. :)
INSERT, DELETE, UPDATE will all fail in the readonly regions. This is normal for Postgres read replicas, we're not doing anything special here.
What we're doing works identically to a vanilla HTTP based app. Requests that modify the DB always run against the primary database. Requests that perform reads _then_ modify the DB always run against the primary database.
HTTP services all have an underlying eventual consistency problem. If you are viewing a page with a database ID on it, then click delete for that ID, the record could be gone before the time the request hits the database (because someone else might've clicked while you were reading).
Does that help? I think we didn't describe this well enough, it's way simpler under the covers than you might expect.
I don't think you're quite understanding how the replay mechanism works. The original HTTP request fails because it can't DELETE or UPDATE something, so the entire request gets re-routed and then handled by the app again, from the beginning. So your SELECTs (as long as they're in the same HTTP request) will always get run against the writable leader.
Think of it like, if your read-only regions don't have anything else stateful they're able to do before the postgres write fails, then their existence is indistinguishable from network latency. An app that doesn't break because of latency won't break because of this.
If the readonlies might do something else stateful and not unwind it on postgres write error, then this approach won't work. (But wouldn't they be buggy anyway? Postgres writes aren't guaranteed not to raise errors.)
That's because the database fail with no changes made, and they retry the whole HTTP request with all business logic in the application re-run against primary instance. So, nothing to do with database-level stuff.
The idea is basically "there is an useful concept of 'group of queries' which is invisible to DB" :)
That's no different than just having a single region serving your application with users that are different distances and latencies away. The one farther away can issue an UPDATE/DELETE at the same time as the closer user, and the closer one would win.
It's all a game of latencies and eventual consistency, so what Fly.io is just treating writes as an HTTP request that has to travel all the way to the primary original, triggered by error an the regional location rather than your application actively doing it.
Clever, but only useful if your “pre-DB-write” work is cheap. For example, I work at a company where part of what we do is matching riders to drivers. This can be very expensive, and a typical flow is:
1) Read current state of riders/drivers from DB (slightly expensive)
2) Solve a vehicle routing problem with the new rider request added to the current state (can be VERY expensive)
3) If there’s a good new solution, commit the changes that the VRP solutions suggest (this is the DB write, and it’s only slightly expensive)
The approach in this blog post would have us duplicating the most expensive thing our app does (step 2 above), for most requests - not good. Much more load on our system, and these already slow writes would take ~twice as long.
I’d hope Fly also lets you configure the load balancer - i.e. have a way to send certain requests to the “writer” nodes by default, vs. in a retry.
Rather than using their suggested "catch writes and throw an exception" mechanism, I would instead write my own fast application logic to identify if something is likely to be a write.
For most of the applications I build the HTTP verb is good enough for this - so I would add a tiny piece of Django middleware which looks for a POST to a non-primary region and sends fly-replay straight away at that point.
I guess where it often gets complex, even with RESTful APIs, is:
- Deletes, puts and patches are basically guaranteed to be writes
- Get is GENERALLY read only, but it often updates caches - and your cache may have similar concerns. Also, sometimes gets write to the DB, i.e. updating a “last seen/last activity” type field
- Posts are generally writes, but definitely not always. Any time you really need a body for a read (big request coming from a browser, or just too much structure in the args to encode in HTTP query params), that read will be a post
I like your approach of short-circuiting and immediately sending fly-replay, but instead of doing it by HTTP method, I’d probably do it by manually marking endpoints as write endpoints. And then I’d also have a catch-all similar to the blog post, based on DB errors, that both sends fly-replay and logs. And then keep track of that log, if it ever happens that’s a sign that you need to mark a new endpoint as a writer.
We follow this pattern as well with a CloudFront -> OpenResty/Nginx router for the different HTTP methods. I've often wondered by CloudFront can't route to custom origins based on request method. You have to do it with a Lambda@Edge function, which is annoying.
GraphQL might work OK though, because it differentiates queries from mutations - so you could have some early logic that says "if this POST request includes a mutation, replay against the leader - otherwise keep running against the replica".
It's true! We designed this specifically because it works with GraphQL. The exception->replay works by default, and it's easy to send early replay command on GraphQL mutations.
What is more you could just have your client send all mutations to one API and all queries to another. I suppose you could do that with REST as well by in Graphql the deliniation is very clear and there are only 2 cases you need to handle.
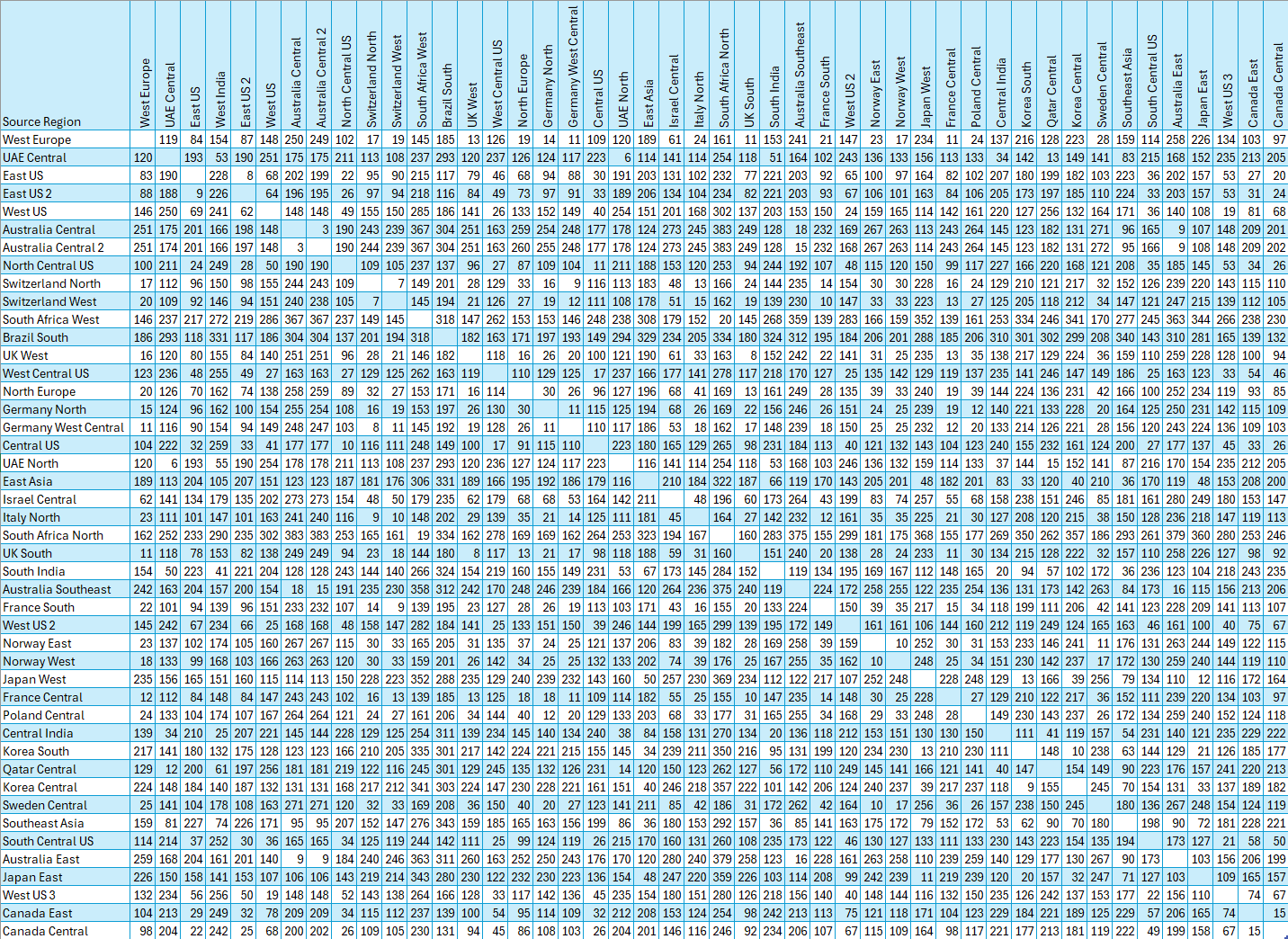
I'm in SJC (San Jose / Silicon Valley) and https://fly-global-rails.fly.dev/regions/syd shows that my replay time to their region in Sydney Australia is between 25 and 45ms. That's pretty quick!
Us West - Australia round-trip for them is ~140ms. And ~50ms seems to be the physical limit unless I messed up the numbers somewhere?
Edit:
Syd-syd response time 138ms
Syd-lax response time 427ms, replay time 16ms
Ok, not sure what the replay time means in this case (extra latency from the cancellation?), but it's not the total cost and you really don't want to send those packets around the world :-)
simonw was referencing the replay overhead number. His request hits Los Angeles first, the rails app in lax says "go to Sydney", and the request gets replayed in syd.
The entire request to Sydney for me (from Chicago) takes 516ms, 15ms of that is "replay overhead".
We need to optimize this. Right now, the edge proxy handles the replay request. So if you hit SJC and a server in LAX handles the request (which is probably what's happening for you), you pay the SJC -> LAX latency penalty before the replay happens.
There's no reason we can't replay from LAX, though, just need to build it.
The try / repeat pattern inevitably needs to do a full round trip multiple times in different regions.
What would be awesome to have is something like this but built on top of envoy postgres proxy or similar where it would know where to send the query to based on the table + column value / pk. But one then rebuilds Yugabyte.
> my replay time to their region in Sydney Australia is between 25 and 45ms. That's pretty quick!
What on earth.. Are people really OK with adding 25-45ms latency because they can't be bothered to route their query to a database that can actually service it?
So far, yes they're ok with that. We can also optimize most of that number away, down to <10ms for almost every app.
They're ok with it because a (valuable) write request that's 10% slower typically comes after a read request that's much, much faster. In this scenario:
> my replay time to their region in Sydney Australia is between 25 and 45ms. That's pretty quick!
The first read only requests were probably <100ms for simonw. The replayed request (that he initiated with a click) was probably 500ms. When a request already takes 500ms, an additional 50ms of latency is basically noise.
The alternative is (often) for them to refactor their apps and then enforce write restrictions on code to make sure random GETs don't write to the DB unnecessarily.
Our goal was to make this work without requiring hairy code changes. People who are ready to do the work to optimize their apps can make things faster and use what we're doing now as a fallback, if they want.
> When a request already takes 500ms, an additional 50ms of latency is basically noise.
I guess it really just depends on what you're trying to do. I would never consider 50ms as noise. It's an accumulation of various things taking 50ms that results in your request taking 500ms in the first place, which is very slow.
I'm interested in this though. I think it's a cool experiment!
Oh yes, that is a fair point. I'm specifically talking about the type of requests that always take 500ms. Almost every HTTP request from Australia to the US takes ~500ms.
This is meant to decrease the unfixable latency, it's probably not a good way to solve app level latency issues.
I think it could be done better by marking requests as either queries or mutations like GraphQL does, then you can just check which it is and forward accordingly.
Although even with REST you should be able to do the same thing, assume GETS can go to the read replicas, should work if you aren’t doing anything weird.
It didn't work cross region because no one builds an app expecting latency between their app server code and database. What we'd see on write requests was something like:
1. Query for data from read replica, perhaps for validation (0ms)
2. Do a write to the primary in a different region (20-400ms)
3. Query primary for consistency (20-400ms)
4. More queries against primary for consistency (20-400ms)
5. Maybe another write (20-400ms)
6. repeat
You can actually use our postgres this way if you want! But it breaks for most apps. It is much, much faster to ship the whole HTTP request where it needs to be than the move the database away from an app instance.
The problem is that most postgres clients can't handle multiple parametric queries in a single connection (necessary for them to be in a single transaction).
This came to light for me as I was trying to build an app on CockroachDB, and the cluster nature of that (at least for geo-redundant setups) implies a non-negligible latency in the low single digits.
I first read the title as "Globally Distributed Progress" and I was like "if an article with this title made it to the front page of HN it must sure be some interesting read.
Me too, having worked with PGSQL in past 15 years, I was expecting...something else. But what bothers me the most is their 2 times quote: "HTTP is cheap". No, it's not. Try having local local servers in remote locations, like ski resorts or country side fair, where internet connectivity is sketchy at best, and then you'll realize how cheap a request is.
HTTP is cheap! Latency is expensive, but all our HTTP shenanigans happen between our proxy and user VMs. We're not inflicting multiple requests on slow clients at a ski resort.
Running a master in us-west and having read replica in europe, what could go wrong ...
My advice is don't do those things in the blog and keep the DB and the app in the same region it will save you so many problems. If you can't just use a DB that was designed for that like Spanner or Cockroach.
I'm a big fan of "pinning" mechanisms where any time a user performs a write to your database you set a cookie that lasts for a few seconds and causes any subsequent requests from that user to go to the lesser, not a replica.
This solves the stale-read-after-write problem and ensures users will see any changes that they have personally made.
This does assume a mostly-reads, occasional-write application (which defines most of the applications I've worked on in my career).
So given that kind of application, what are the problems I'm not considering that I should look out for with a read-replica on a different continent?
Of the many things that can go wrong, the one I would be most worried about would be replication lag causing the disk on the primary to fill with WAL logs bringing down the primary, or if you have limited the WAL logs, the replica not being able to keep up and detaching from the primary causing stale reads.
Also long distances will make replication latency increase so unless _all_ requests are sent to the primary region you will likely have a read after write state data situation unless you go out of your way to ensure consistency
Stale replicas are a "stop serving requests from a particular region" problem. We pretty aggressively monitor these and consider things broken if replication is lagged more than about 10s.
One thing about running thousands of DB clusters (which we did at Compose.com before this) is, these problems exist even without geo replication. And they exist at such a scale that you have to be good at handling them. Geo replicas are _more_ prone to these kinds of issues but we already had to be good at handling them.
That is good and should prevent against bringing down the primary. There is still the issue with being able to get that region back online once replication is severed, which isn't always possible even with co-located systems.
Is the WAL log situation you describe here a likely function of both distance (hence latency) and volume of writes? So if I have a high volume of writes AND I'm trying to replicate them half way around the globe I'm more at risk of running out of WAL log space on the leader?
Yeah, if you are doing global replication you are much more likely to fall behind so you should have aggressive monitoring on the replica to remove it if replica lag gets to high, that will prevent the primary from retaining WAL files for too long.
It also means you will need to be able to resync the replica from a backup once write volume calms down.
All the things that can go wrong with globally distributed databases. You can just run an HA cluster in a single region if you're looking to keep it simple, just the same way you can run a single-region app on Fly if you like.
We try to go out of our way to say that this stuff isn't a perfect fit for every application or a "best" way to do things. I think if a deployment like this is attractive for your application, you probably know it. I'm certainly not going to evangelize against people scaling up single-region databases!
It reminds me of Yugabyte, which is Postgres compatible
> YugabyteDB is the open source, distributed SQL database for global, internet- scale applications with low query latency, extreme resilience against failures. *
However Fly is nicer from a developer's point of view, because it doesn't require you to learn a new query language, you can write good old Postgres.
> Successive YugabyteDB releases honor PostgreSQL syntax and semantics, although some features (for example those that are specific to the PostgreSQL monolithic SQL database architecture) might not be supported for distributed SQL. The YSQL documentation specifies the supported syntax and extensions.
It is psql compatible, but you may run into missing features, so you will have to find a way around that. The documentation says that their latest release is based on psql 11.2, and psql 14 will be released soon.
We observed two things from developers when we started working on this:
1. The first thing we did was give them CockroachDB. Modeling data for geo distributed Cockroach is conceptually similar to yugabyte. It's not easy, though, to do that modeling. For read heavy apps most devs didn't want to do the work.
2. We also experimented with cross regions writes at the DB level (both with Postgres and Cockroach). The failure cases on those were bad. Apps are pretty naive about queries, so interleaving writes with >10ms of latency between reads resulted in really slow requests. These were pretty frequent! Most apps broke if the devs didn't carefully optimize that sequence.
The free we're going for here is "free for most developers". Changing a data model or optimizing how an app talks to a database wasn't quite free enough for our purposes, and neither were necessary for the types of workloads most people deal with.
They _definitely_ need to use something that's not-just-postgres to do multi region writes or distribute write heavy workloads. That's why we wrote the whole section on graduating to Cockroach. Graduating from Postgres to yugabyte also works!
We're talking about a different level of "easy" I think.
Easy: asking devs add a gem to their app.
Hard: asking them to write migration code of any kind, much less understand tablespaces and replica placement.
You're advocating something we spent a lot of time trying! Boring Postgres read replicas worked for almost everyone we worked with, and it works for the vast majority of what full stack folks are already building. Our infrastructure will work great for the ones who need Cockroach/Yugabyte, too! That's specifically why we covered it in our post. :)
Hey, so I’m actually in a hunt for a multi tenant psql solution and so far, I’m settled on yb but can try other things out, would you be up to discussing my use case? What would be the best way to get in touch?
> Hard: asking them to write migration code of any kind, much less understand tablespaces and replica placement.
By that standard, any kind of global consistency (or even weakened consistency of various kinds, but maintaining some desirable properties) will always be 'hard'.
It will always be hard. Consistency + latency is a huge problem.
We can give _most_ developers the benefit of globally distributed postgres without causing consistency issues, though. Read replicas are simple to think about and reasonably easy to write standard code for.
All the next-gen distributed SQL databases are neat. We are definitely not trying to compete with them; that's not at all where we're heading (though we'd be happy to work with them to bring their databases to our platform).
This is just a neat hack you can do with totally standard Postgres. It's a thing other people do outside of Fly; we just like how easy you can make it if you can program both the CDN and the applications.
> It is much, much faster to ship the whole HTTP request where it needs to be than the move the database away from an app instance.
Does that mean that the app server would just fail, and then your network replays the same HTTP request (made by the client to the edge), toward an instance running the app server inside the region where there the Postgres primary instance is running? If so, you should then be able to figure out which client request provoked the SQL error and the app server would report some errors, right? Otherwise, the app server should be able to tell you if it failed because the Postgres server does not support write statements, which would require some minor adjustment in the app server code, isn't it?
I am sorry if I missed something from your description, but I am trying to figure out what the flow would look like. Thank you!
> It is much, much faster to ship the whole HTTP request where it needs to be
If you're already routing at the HTTP level then why not just route the request based on the HTTP method? (assuming the handlers for those are properly implemented.)
Why not just route a POST request to a backend connected to a writable database? And GET to a read-only database? I don't understand how it's any kind of an optimization to be continually bouncing queries out of the read-only replicas because Postgres threw an error.
I agree with you, but I just was trying to understand the fly.io post. They also wrote:
"Most GETs are reads, but not all of them. The platform has to work for all the requests, not just the orthodox ones."
So I think it all depends on which level of the application you take the decision to gracefully fail and replay the request elsewhere. In some case, it is trivial: as soon as you see a POST/UPDATE/DELETE, because you trust your app; sometimes you may need to take the decision later, or at a lower level.
In the simplest scenario, fly.io could just forward the request to the right region, without even bothering the app server to reply with an error, but that would work only if GET requires no writes.
We can give people a library that catches Postgres readonly errors and make it a reasonably standard experience. We can't ensure that peoples' apps have good write hygiene. We _can_, though, educate people and tell them what to look for when they're trying to optimize performance.
There's also the graphql problem (and really any kind of non-rest RPC). It's somewhat rare that applications use HTTP verbs appropriately, APIs tend to bypass HTTP methods.
You can't _only_ do that, but it seems like a reasonable place to start for REST API's. I don't think there's anything to change in your product, just that the docs should recommend ways to reroute as early as possible in a request lifespan (eg, at the routing layer or before).
I'd worry about a POST route that does some expensive/slow reads/computations in the first half of the request, and then only writes at the end – lots of lost time! Would have been much better to say, hey, for this route (or for any POST route in _my_ application), please bounce to the region with the primary db instance.
Actually, while that could be done at the application level with reasonable latency, it'd probably still be better to allow the user to write some rules at the proxy layer for the "first guess".
I get what you're trying to say, but what I'm saying is that the approach you're proposing simply doesn't work. Sure, it'll route POSTs and PUTs to the write master, that part will work fine. But GETs will randomly bomb when they throw an UPDATE at their read replica. We can't predict which of those GETs will break on behalf of our users, and the one thing we're trying to avoid asking our users to do is to do complicated surgery on their applications to make them run well on us.
Like, I think it would make sense to have the feature that routes by HTTP verb! But it would be dangerous to promote that as a write-steering feature.
No, I'm saying you do both - proactively steer routes that are obviously going to write to the primary, and use the clever retry technique for everything else.
The retry technique is something you must do as a fallback, but it causes additional latency and should be avoided when you know ahead of time that the request involves a write.
Again, the application engineer should be the one responsible for writing these rules, whether in their application's routing/middleware layer (easier) or in flys proxy layer with a rules engine (faster).
We'll accept any container that a Docker registry will; you don't have to use Docker to build your container instance (`flyctl launch` will build an application from a buildpack). You can run systemd in a container.
We don't use Docker to run containers; in fact, we don't run "containers" at all. Instead, we transmogrify OCI containers into root filesystems for Firecracker micro-vms. Your "container" runs as a virtual machine with its own Linux kernel. You can do whatever you'd like with it.
Is there a reason you need systemd? You can build a pretty minimal image with just the go binary in it (assuming you have statically linked it using musl).
At Bugout, we don't use docker. We deploy our code directly to machines over SSH and use systemd to coordinate deployed services, run timers, etc.
Building the go binary is not a problem, but determining how the go binary runs, what it needs in order to be functional, etc. is where systemd comes into our setup.
I know this is hacker news and all and you’re trying to be fun, but as I’m looking at platforms like fly for a future saas, the first sentence (cool hack) rubbed me the wrong way. Would rather hear “we found an elegant design” and are working hard to make it bulletproof… etc.
Databases are like that, the place to get serious.
Sure I won’t let it deter me from a proper eval, but I could definitely see it scaring away suits.
We are at the stage where attracting developers and scaring suits is probably good.
I'd have a hard time calling something I was partially responsible for elegant, though, so this might just be our self deprecating nature rearing its head.
>We are at the stage where attracting developers and scaring suits is probably good.
As a developer the way it was written scared me off. It reads like one of those recipe sites that game Google by adding a nonsensical story to the recipe. It seems like it took half the article to get to your "one trick". And ultimately you didn't deliver what the title teased.
I tried this a few months ago. Many features were missing then. I couldn't set up backups, and connect directly to `psql`. It was such a pain. I don't know if they've addressed those issues yet. It'd be a hard sell for me to store a database system for a production app in a Docker image.
Just a note about directly managing Postgres here: we launched Postgres like, a minute ago (a couple months in normal people time). For a pretty long time, you couldn't do any real persistent storage on a Fly instance; we were still mostly targeting edge applications, where people slice components of their apps off to run closer to the edge.
I think it's safe to say that while we still love edge apps and are committed to them long term, we've switched gears towards full-stack applications (that is, we've gotten a lot more ambitious about what we want to be a good platform for). So this stuff is shaping up pretty quickly.
Postgres (and volume support) happened at about the same time as private networking did (Postgres was our first internal application for private networks). In January, we started doing user-mode WireGuard, so that `flyctl` runs its own TCP/IP stack and speaks WireGuard directly, without involving the OS (so you don't need root to use it). User-mode WireGuard gave us `flyctl ssh console`, and is also the way we do direct `psql`. There's more stuff in that vein coming; hopefully, it's gotten a lot easier to manage Postgres as `flyctl` has gotten more capable.
Where we want to be is for it to be trivial to run something like Postico.app to talk to a Fly Postgres database. You can do that now, but it's not yet _totally_ trivial. Hopefully you can sort of look at `flyctl` (it's open source) and see how that'll work.
It's better, but still beta. We handle backups and you can connect directly to psql. We also added migration support as part of app releases. The global distribution feature, though, works with any database, not just our postgres.
Between you and me, we tried really hard not to build a Postgres service. We're committed now, it's gonna be good. For future DBs we plan to get big enough that people like Timescale to ship their products on Fly infrastructure.
You could run your own PG by modifying that app. Right now we're calling it "automated" and not managed, though. All alerts about health and other issues go straight to customers, we don't have DBAs that will touch these things yet.
How are POST requests replayed into different regions? Does your edge proxy hold the whole POST requests (body and all?) just in case it needs to be replayed?
Fly.io and the Postgres service look great. Do you have a roadmap for future regions? (I'd personally love to see Korea.) If I may ask, do you use major cloud services or run your own machines, and how easy or hard is it for Fly.io to add new regions?
We don't have a firm roadmap for future regions, but Seoul is high up on my wish list.
Our infrastructure is all dedicated hosts, mostly running in Equinix facilities (we buy a lot of servers from what used to be packet.com).
New regions are hard in one particular way. Since we accept anycast traffic, ever new region has to be anycast-able for us. We outsource anycast management so we're kind of stuck waiting on other providers to opt in to a region.
When we get to a scale where we can manage our own anycast and decide we want to, we will be able to ship new regions relatively quickly. Some places are harder to get servers to than others, but we don't actually need a very large footprint to get started.
{kind=link}
So your computer has memory banks that (as a rough first approximation) each get ~10x bigger, but with ~10x greater latency. The neat part though is that global consistency for writes happens with L1 and L2 working together, so pretty damn high up in the hierarchy. In contrast distributed applications typically at best will have a write through cache where global consistency happens all the day down at the actual data store. Exploring the idea of distributed MOESI where one client, because they had the permissions to write something in the first place, can then be the owner for that database row as it's still being flushed out seems like a great basis for a distributed system that might not even need the dedicated datastore at all anymore, but a sea of clients participating in coherency and replication. Albeit this has oodles of consistency and availability problems that very well might kill the whole concept, like how MOESI would absolutely fall over when trying to hotplug CPUs at arbitrary times.