@dang I think worth to place the year (1993) on the post.
...
It's quite refreshing to see some results of this competition specially in comparison with the M5 that is the most relevant competition in time series.
For practitioners one thing that is important to consider is that this competition had datasets with way longer time intervals (I think M5 has a lot of time series but in a short horizon) and the methods used back in the day was way more sophisticated.
I didn’t know what those things are so here’s what I found out:
Gradient Boosted Trees: This is a machine learning technique used for predictive modeling. It involves creating a series of decision trees, where each subsequent tree corrects the errors made by the previous ones. Think of it like a team of experts working together, where each expert specializes in fixing the mistakes made by the previous experts. This iterative process leads to a strong predictive model.
Ensembling: Ensembling is a strategy in which multiple individual models are combined to create a more robust and accurate prediction. It's like taking the opinions of multiple experts to make a better decision. In the context of gradient boosted trees, ensembling involves combining the predictions from multiple trees to get a more accurate overall prediction.
Secondary Ensembling Scheme: This refers to an additional layer of combining models to further improve accuracy. It's like having a group of experts (the gradient boosted trees) collaborate and then having another group of experts (the secondary ensembling scheme) collaborate based on the first group's insights.
So, "gradient boosted trees fed into some secondary ensembling scheme" means using a combination of decision trees that correct each other's errors, and then taking the outputs of these trees and further improving their predictions through another layer of combining models. This approach often leads to highly accurate predictions in forecasting tasks.
> This chapter reports on a competition run through the Santa Fe Institute in which participants from a range of relevant disciplines applied a variety of time series analysis tools to a small group of common data sets in order to help make meaningful comparisons among their approaches. The design and the results of this competiton are described, and the historical and theoretical backgrounds necessary to understand the successful entries are reviewed.
The competition has already been run. It's from 1993.
I seriously think the long term future of computing is massive scale time series correlation with analog hardware that doesn't do discrete processing with I/O and on/off transitors
I vomited my theory down years ago - though I probably need to refine it.
Transformers IMO are basically pointing towards time series predictions as being the root of epistemological grounding for "intelligence"
We probably need a new type of computer to realize this (nb. A previous good friend did bring up the point that digital sampling at a high enough rate could approximate biological "continuous" sampling - but I think it's flawed theory)
I seriously think the long term future of computing is massive scale time series correlation with analog hardware that doesn't do discrete processing with I/O and on/off transitors
It's funny you say that. Over the past few months I've ordered copies of almost every book on analog computing that Amazon has, planning to do a deep dive into the "current" state of that, with an eye towards figuring out if there's some "there, there" to explore. I say "current" in scare quotes because there aren't a lot of recent books on the topic, given that analog computing mostly died out decades ago. There does seem to be a bit of a limited resurgence of interest recently though.
Transformers IMO are basically pointing towards time series predictions as being the root of epistemological grounding for "intelligence"
I've also been spending some time studying neuroscience and the literature on "spiking neural networks" based on a vague hunch that that and the analog stuff might tie together into something interesting.
All of that said, I do think that it makes sense to think about hybrid analog/digital systems since digital has so many advantages, especially in terms of flexibility and programmability. The question then, is something like "what's the best architecture that lets you best take advantage of both analog and digital styles of computation"? I won't pretend to say I know the answer to that, but that's a path I'm trying to explore a bit.
My perception is there has been a steady stream of analog circuit work in recent decades (not quite pure "analog computing", but related to it) due to the integration of analog signaling into cell phone chips that otherwise are digital (see https://en.wikipedia.org/wiki/Mixed-signal_integrated_circui... ); not sure if any of that is relevant to your explorations.
...Using the Visual phototransduction cascade [1] to turn light into voltage.
That signal is then transmitted through the optic nerve, pre-processed for reaction and early processing, and then hits the visual cortex where it flops around and other sensory systems combine their voltages trying to make meaning of things in increasingly abstract ways.
That is basically the same process used for all other senses as well, but just using different sensor methodologies
However the actual data uses the same medium of chemical-voltage transport throughout the PNS and CNS.
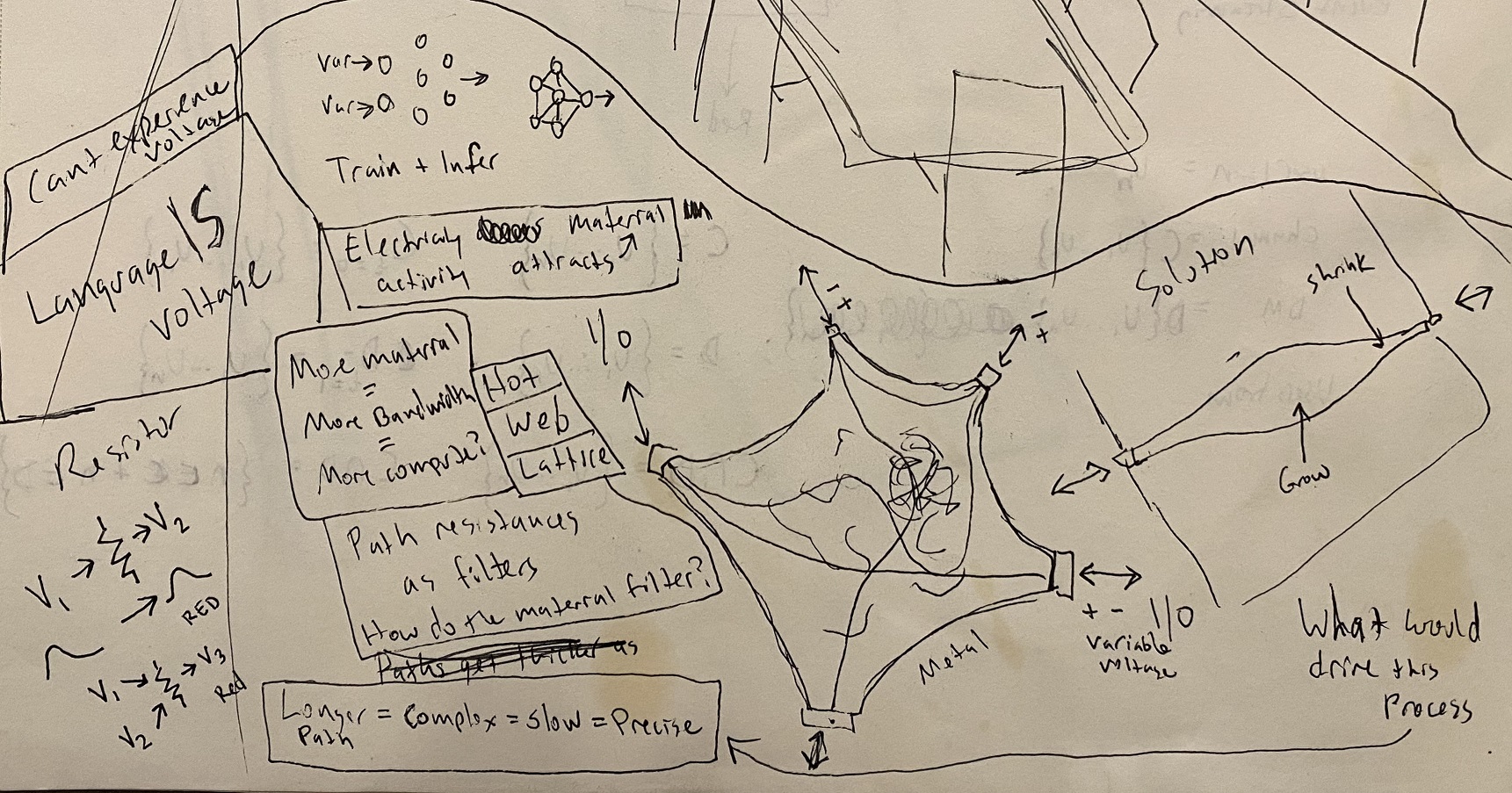
So using this construct, you need a hardware system that can remap pathways between sensors without rigid architecture and via processes that are emergent based on environmental changes.
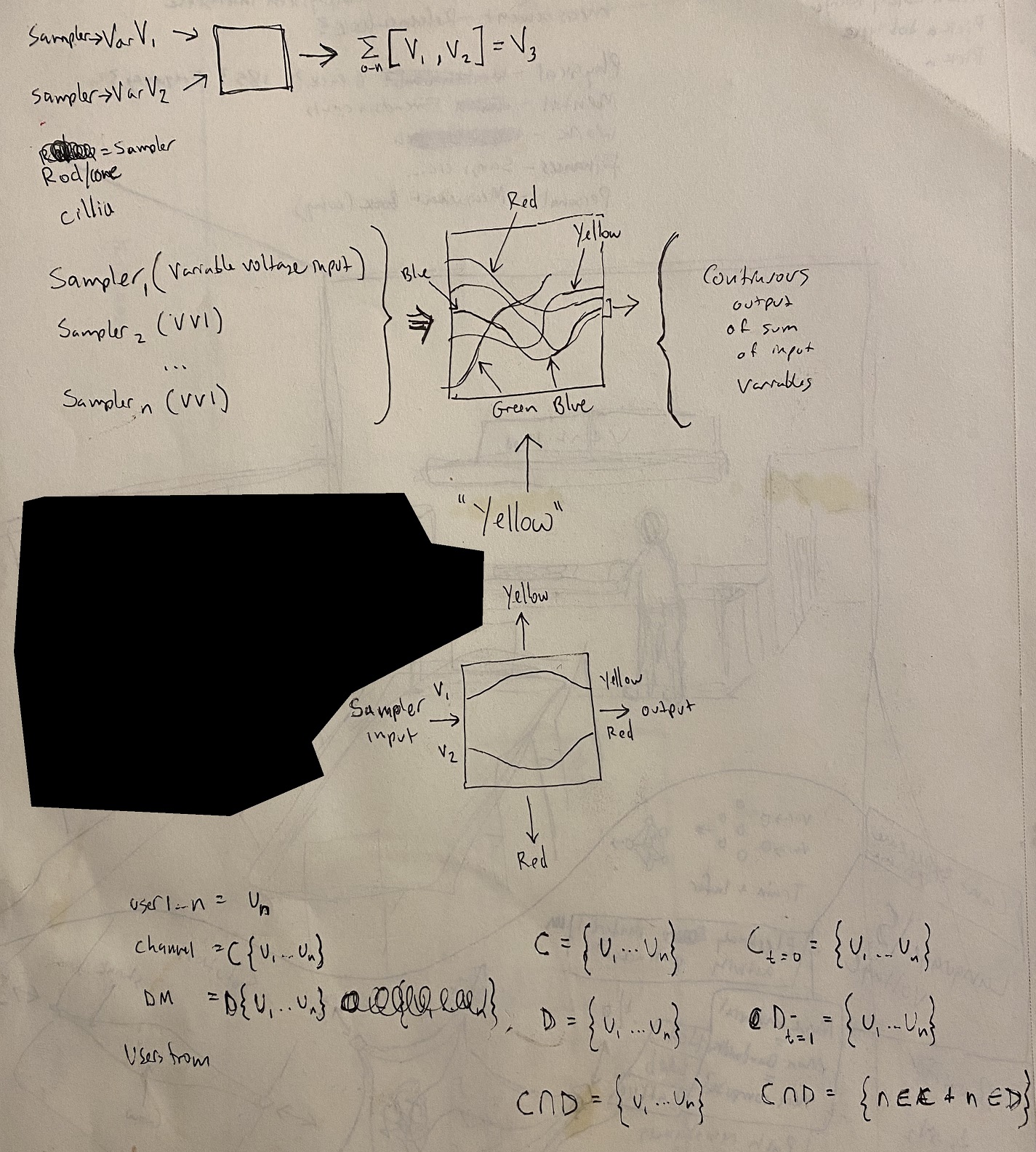
I propose then that a liquid electro-chemical substrate that is materially additive (accretes more permanent power flows) depending on how much power (P = Volts * Amps) is flowing between nodes. That substrate then fills a cube covered in anodes and cathodes that represent individual sensor inputs/outputs.
It's basically recreating a human nervous system with a gel like substrate as the "brain" that can "rewire" itself infinitely as sensors are changed or otherwise.
I have a drawing of this but haven't uploaded it anywhere. If you're interested I'll scan it in
So using this construct, you need a hardware system that can remap pathways between sensors without rigid architecture and via processes that are emergent based on environmental changes.
Yep. Only in my case, my day-dreaming about this to date had me considering using digital components (digital switches, multiplexers, ADC/DAC's, etc) to build the configurable routing part. Not to say that I'm convinced that is the right approach, it's just some stuff that was bubbling around in my head.
I have a drawing of this but haven't uploaded it anywhere.
That would be great. And if you'd like to move this discussion to a different forum (aside from comments on an HN thread) feel free to ping me directly @ prhodes@fogbeam.com. Or keeping it here is fine. Either way's good with me.
It’s a fairly esoteric topic, but reservoir computing can be done in an entirely analog manner (analog reservoirs + a weighted linear sum via op amps; I don’t know how you dynamically update the sum weights in an analog fashion but I assume it’s possible) and some people work on it.
First, that user just posted a link, so accusations of "stealing" are out of line; take it up with Santa Fe Institute. Second, your response to a link to a PDF paper is to post a Twitter link? That's laughable. Well, I laughed, at least.
{kind=link}
{kind=link}
...
It's quite refreshing to see some results of this competition specially in comparison with the M5 that is the most relevant competition in time series.
For practitioners one thing that is important to consider is that this competition had datasets with way longer time intervals (I think M5 has a lot of time series but in a short horizon) and the methods used back in the day was way more sophisticated.